KV cache 量化之KIVI
文章目录
高效地服务大型语言模型 (LLM) 需要对许多请求进行批处理,以降低每个请求的成本。然而,随着批量大小和上下文长度的增加,存储注意力键和值以避免重新计算的键值(KV)缓存显着增加了内存需求,并成为速度和内存使用的新瓶颈。此外,KV缓存的加载会导致计算核心空闲,从而限制了推理速度。减少 KV 缓存大小的一个直接有效的解决方案是量化,这会减少 KV 缓存占用的总字节数。然而,缺乏深入研究KV缓存的元素分布来了解KV缓存量化的难度和局限性。
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache | PDF
背景
per-token and per-channel quantization
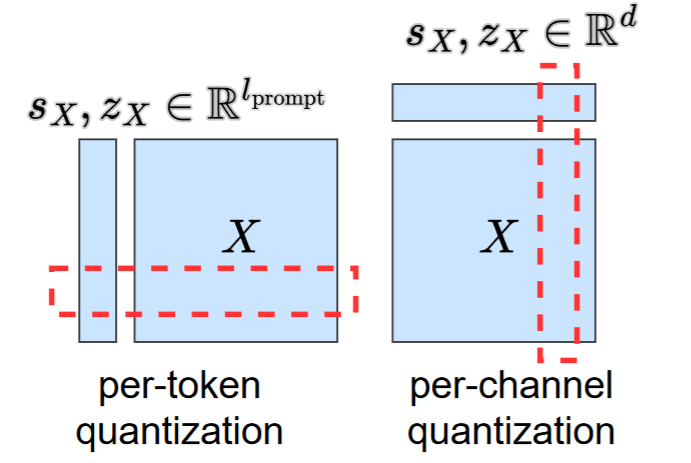
- per-token量化,将每一个token做为量化的单位
- per-channel量化,将token中的channel作为量化单位
Attention Inference-Time Workflow
在Prefill 阶段,例如一个输入$\mathbf{X} \in \mathbb{R}^{b \times l_{\text{prompt}} \times d}$,$b$ 是batch size,$l_{prompt}$是输入的prompt词序列长度,$d$ 是hidden size,
$$
X_{K} =XW_{K} \\
X_{V}=XW_{V}
$$
$W_{K},W_{V}\in \mathbb{R}^{d \times d}$,$W_{K},W_{V}$是对应的权重。获得$X_{K},X_{V}$后需要缓存,也就是KVCache。
在Decoding 阶段,输入token的embedding $t \in \mathbb{R}^{b \times 1 \times d}$, 那么
$$
t_{K} = tW_{K} \\
t_{V} = tW_{V} \\
$$
更新KVCache
$$
X_{K} = Concat(X_{K},t_{K}) \\
X_{V} = Concat(X_{V},t_{V})\\
$$
然后计算attention的输出
Motivation
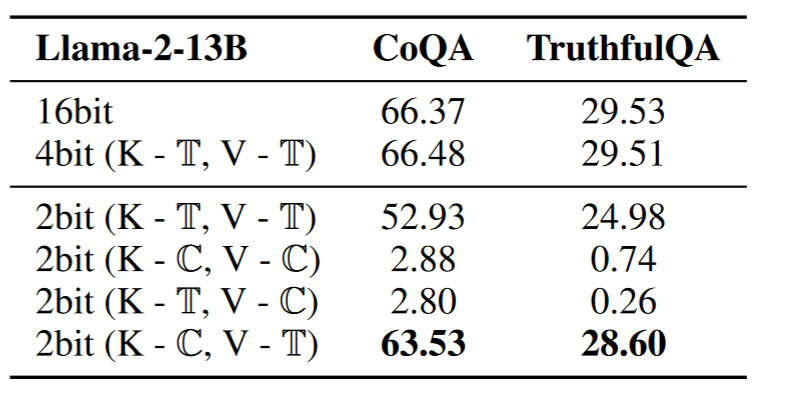
可以看到在4bit量化时,K,V按照per-token的方法,在CoQA以及TruthfulQA可以保持精度,但是2bit量化时,精度会崩塌。
KIVI的目的是解决KVCache 2bit的量化问题。
从表中可以看出,最好的方法是K按照per-channel,而V按照per-token
为什么K-T,V-C的方式最好
量化嘛,肯定是要看数据的分布
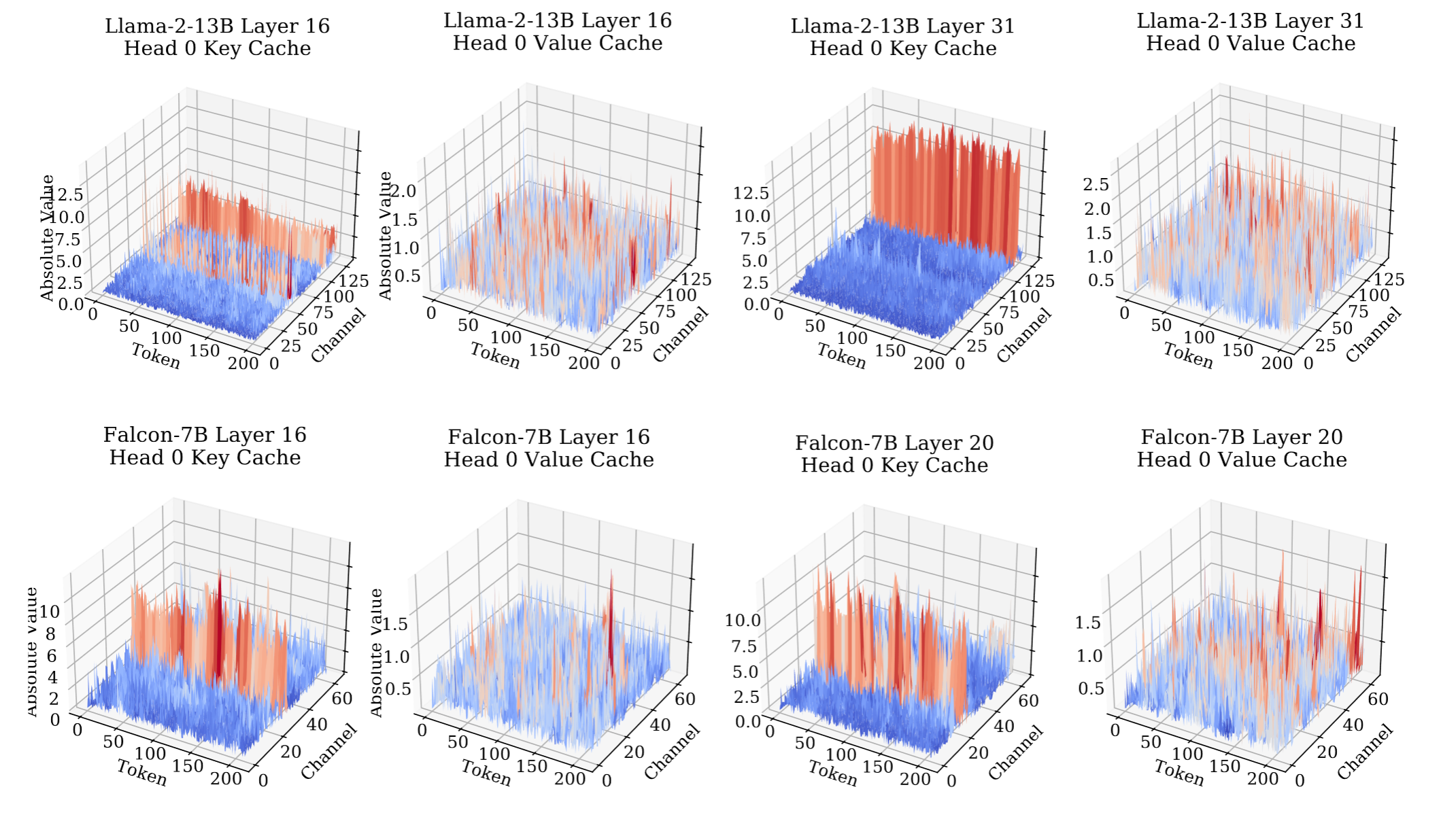
从上面图中可以看出KVCache中的数据分布。
对于Key_Cache, 不同的token分布情况类似,异常值集中再特定的几个channel中
对于Value_Cache,整体数据分布比较平缓
量化实现
KVCache 与普通量化的不同: KVCache是一个stream,会随着上下文增加而增加。不像权重量化,是固定大小,不随着推理变化而变化。
Per-token的方式,可以很好解决和规避增长的问题,每次增加一个token的数据,只用对新增的token数据单独量化,与之前的Cache互不影响。
Per-Channel的方式,问题在于量化的数据一直在增长,比如token增加,channel的长度也会增加。
对于K Per-token量化,对于V Per-Channel量化,重要的是怎么解决Per-Channel的问题。
方法
将每个K cache,进行分组每G个token一组,进行分组量化。余剩下的进行单独量化。
$$
group\_part \ X_{K_{g}} = X_{K}[:l-r]
$$
$l$为token数量,$r$ 为$l%g$, $l-r$是$g$的整数倍
$$
residual\_part \ X_{K_{r}} = X_{K}[l-r:]
$$
只存储$Q(X_{K_{g}})$ 也就是分组的部分,进行量化。$X_{K_{r}}$ 不量化。在decoding 阶段,新的key_cache,会被添加到$X_{K_{r}}$中,当大小满$g$时,进行量化并添到$X_{K_{g}}$中。
在做attention时,进行混合精度矩阵乘法
$$
A_g = t_{Q} Q( X^\top_{ K_g} ) \\
X_{K_{r}} = Concat([X_{K_r},t_{K}]) \\
A_{r} = t_{Q}X^\top_{K_{r}} \\
A = Concat([A_g,A_r])\\
$$
该矩阵乘法使用Triton实现。
原文作者: weikangqi
许可协议: 知识共享署名-非商业性使用 4.0 国际许可协议