Atom低比特权重激活以及Cache量化
背景
- 流行的量化方案LLM.int8(),SmoothQuant(例如 8 位权重激活量化)无法充分利用现代 GPU 的功能,例如 int4计算,从而导致性能不佳。例如,A100 GPU 可以达到 1248 TOPS(INT4)和 624 TOPS(INT8),而带有 Tensor Core 的 FP16 只能达到 312 TFLOPS。然而,INT8量化仍然无法利用低位运算,例如INT4 Tensor Core。
- OmniQuant等提出将 LLM 量化为 4 位,但是PPL增加很多。
方法
整体架构
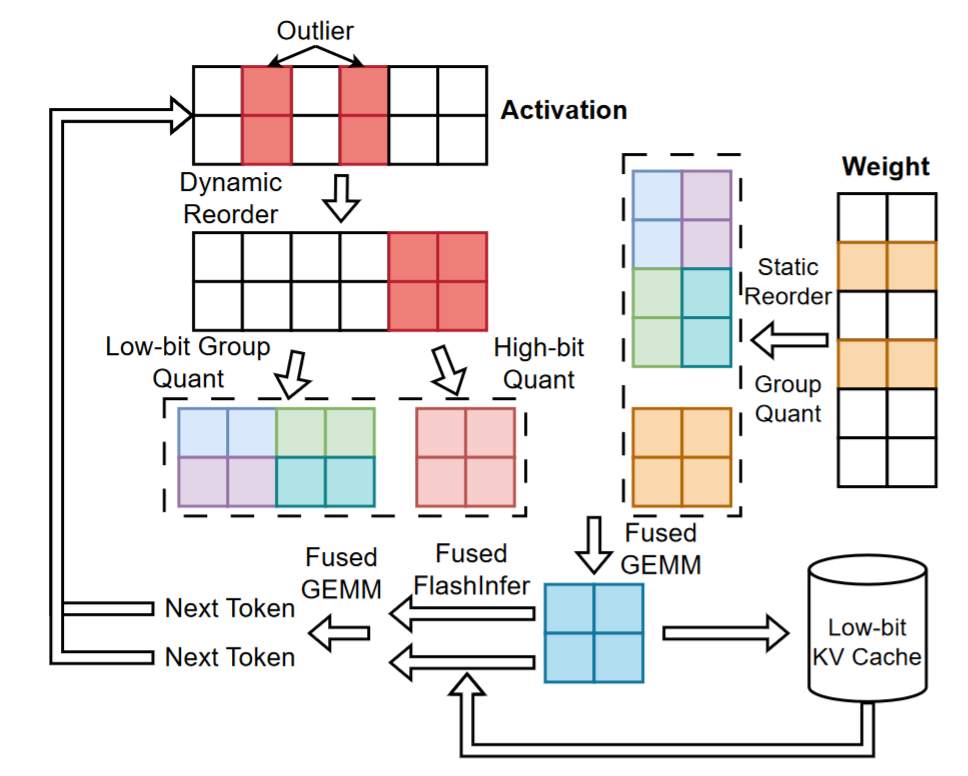
主要做了
- 通道重新排序后混合精度
- 细粒度分组量化
- 动态激活量化以最小化量化误差
- KV-缓存量化
混合精度量化
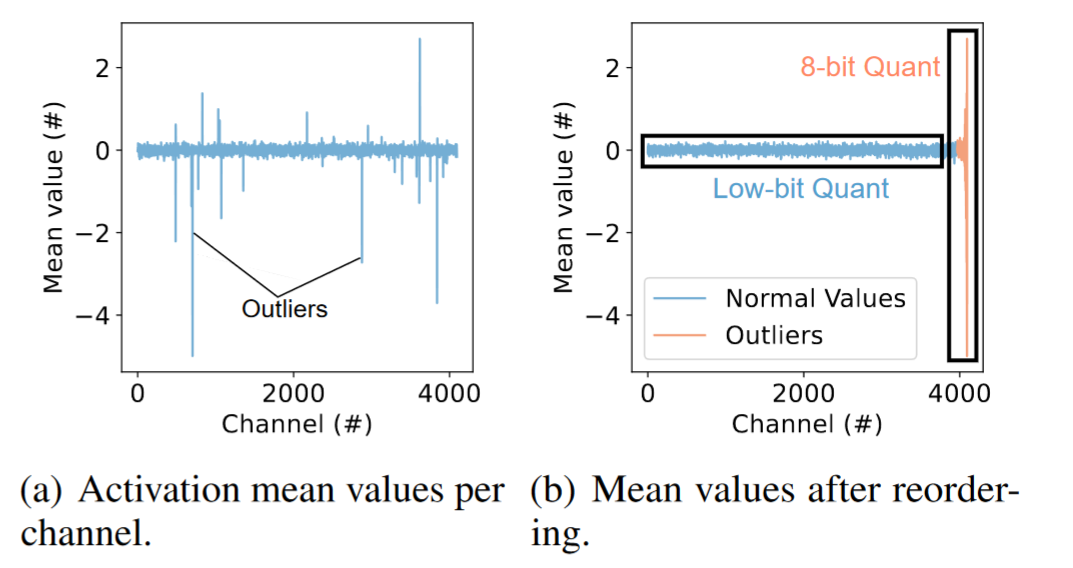
每个通道的激活平均值,有一些通道有很大的异常值,这些值很大的影响了量化精度,论文对通道进行了重排,将这些离群通道重新排序到矩阵的末尾,并使用更高的精度(int8,FP8)来量化它们,同时保持常规的内存访问,去除异常值后,剩余通道更加均匀,可以通过低位值有效表达。Atom 对异常值应用 INT8 量化。
这样会可能对内存重排,效率肯定不会高,
怎么解决这个问题?
为了在保持常规内存访问的同时应用混合精度量化,Atom 重新利用了RPTQ中的重新排序技术。
权重矩阵的重新排序会产生一次性成本。然而,激活矩阵的重新排序仍然需要在线执行,这可能会很昂贵。
为了缓解这个问题,Atom 将激活矩阵重新排序运算符融合到先前的运算符中,从而将重新排序开销显着降低到运行时的 0.5% 以下。
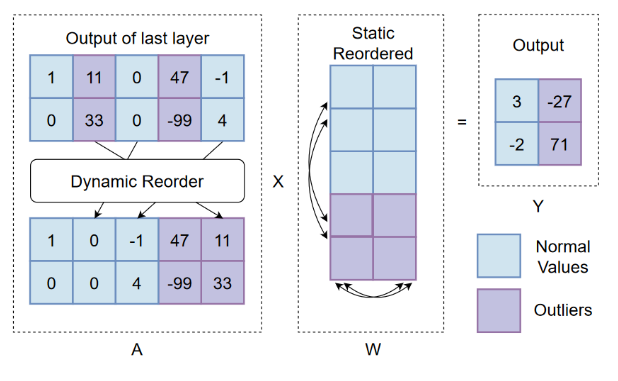
为了保证计算结果的等价性,需要使用相应的激活重新排序索引对权重矩阵进行重新排序
RPTQ
RPTQ(Reorder-based Post-training Quantization)是一种针对大型语言模型(LLMs)的量化方法,它通过重新排列激活中的通道并将它们分簇进行量化,以降低通道范围差异的影响。为了解决通道重排的耗时问题,RPTQ采取了以下策略:
避免显式重新排序:RPTQ通过避免在运行时显式重新排列激活中的通道来减少存储和计算开销。这种方法避免了将不同通道的数据从一个内存位置物理移动到另一个位置,从而降低了重排过程的耗时。
权重和激活的重排序:作者重新排序了线性层的权重,使它们能够直接按照排序顺序产生激活。同时,修改了LayerNorm的方法,使其能够直接产生重新排序的激活,从而省去了在推理过程中进行显式通道调整。
集成到层归一化操作和线性层权重中:RPTQ将通道重排集成到层归一化操作和线性层权重中,以最小化相关的开销。这种方法有效地减轻了通道范围的差异,并且通过操作融合,避免了显式重新排序的操作,使得RPTQ的开销几乎为零。
工程优化:为了减少内存重排的开销,RPTQ提出了一些工程优化措施,例如把重排操作融入到layernorm层中,直接在layernorm刷回内存时按新排序的index进行写入。同时,调整了weight顺序,允许线性层直接接受重排的激活值,同时自身也输出重排的激活值。
细粒度的分组量化
即使 Atom 分别量化异常值和正常值,由于 4 位精度的表示能力有限,后者仍然难以准确执行。为了进一步提高精度,广泛采用组量化,它将矩阵划分为子组并在每个子组内执行量化。比如,例如,组大小为 128 意味着 128 个元素的每个连续序列都被视为单个组,该组是独立量化的。
并实现了一个融合GEMM算子
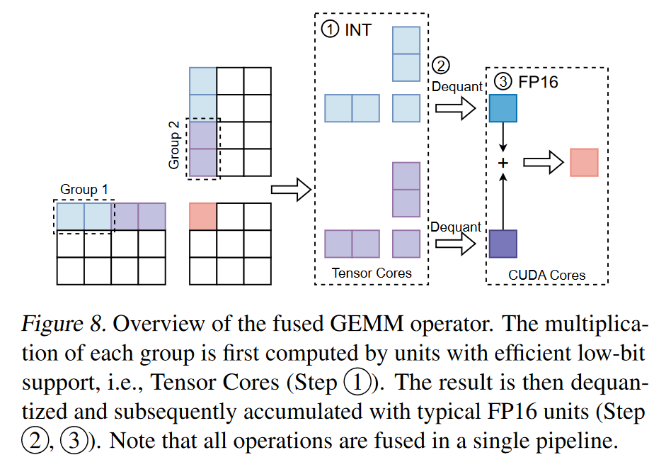
每一分组,可以利用Tensor Core进行高效的计算,相加时,反量化为FP16,利用CUDA Core计算。
动态量化
如果基于校准数据静态计算量化参数,因为实际输入可能具有不同的局部分布,上面的细粒度分组量化的优势会减弱。
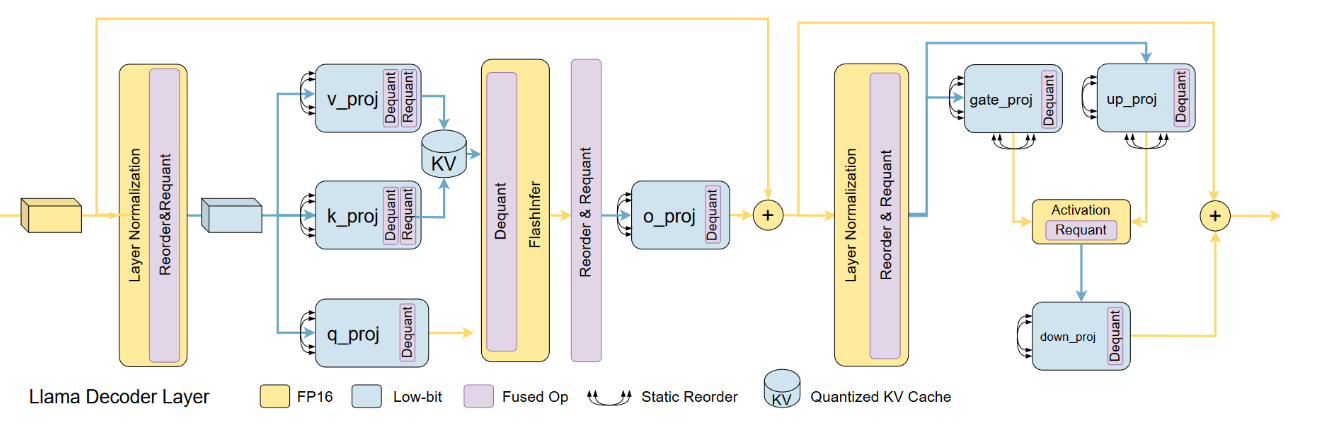
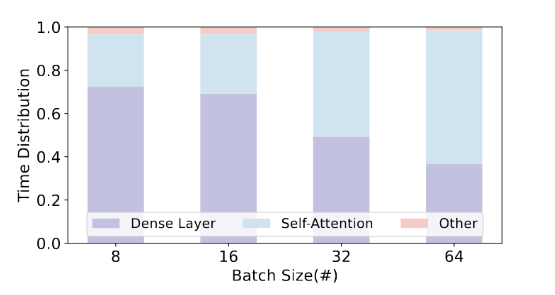
因此,Atom采用动态量化,在推理过程中为每个激活矩阵定制量化参数。为了控制动态量化的开销,我们将量化操作融合到先验运算符中,类似于 ZeroQuant 的实现。由于附加运算符是逐元素的(具有缩减和逐元素除法),因此与耗时的密集层和自注意力层相比,融合运算符的运行时间仍然可以忽略不计。如下图LLama-7b的模型推理
为了在吞吐量和准确性之间取得平衡,我们选择对称量化并仔细选择剪辑阈值。在量化权重矩阵时,结合了 GPTQ。
原文作者: weikangqi
许可协议: 知识共享署名-非商业性使用 4.0 国际许可协议