KVQuant
KVQuant 主要做了
- 发现每通道量化为Key提供了显着的准确性优势,但对Value却没有。也就是K按照Token量化,V按照Channel量化
- 在RoPE前对Key进行量化,从下图可以看出
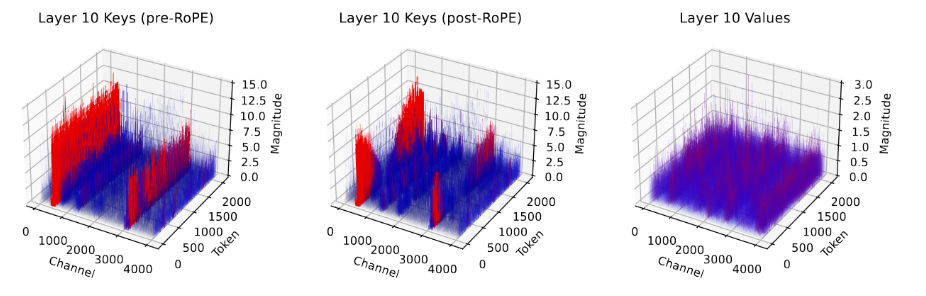
- nuqX:每层敏感度加权非均匀数据量化,与SqueezeLLM的方法相同,只不过KVCache数据是增长的,论文用离线标定来解决,而KIVI使用分组来解决。
- Dense-and-Sparse Quantization: 类似SqueezeLLM的方法相同,只不过从而不是每一层的单个异常值阈值,变成每个向量或者Token或者channel。更细粒度。使用离线使用数据集校准。
- Attention Sink-Aware Quantization注意力沉降感知量化:在大语言模型的前几层,模型会将大量注意力分配给第一个词元(token),即使它在语义上并不重要。这个现象是因为模型倾向于把第一个词元当作“沉降点”或“注意力聚集点”(sink)。由于这种注意力下沉现象,模型对第一个词元的量化误差特别敏感。也就是说,量化误差在第一个词元上会更显著地影响模型的表现。为了解决这个问题,在量化时将第一个词元保留为FP16(半精度浮点数)可以带来困惑度(perplexity)的提升,特别是在2位(2-bit)量化时效果明显。当第一个词元保留为FP16时,量化校准过程也会忽略第一个词元的影响。这意味着在推导自定义数据类型(nuqX)和校准Key的缩放因子及零点时,第一个词元不会被考虑。
原文作者: weikangqi
许可协议: 知识共享署名-非商业性使用 4.0 国际许可协议